Basic SSRL and FlowCapsules
Self-Supervised Image Representation Learning (often shortened to SSRL) is a method of learning feature-based representations of a dataset of images without labels. Although sounding very similar to the latent space representations of Autoencoders, these differ and improve on those by being transformation invariant. The goal of these models is to generate the same representation of an object without any form of rotation or translation affecting it. This allows any sort of model using these representations to gain more information about the objects within the image rather than just the image itself, helping with many complex computer vision tasks.
This post will cover some of the most basic forms of SSRL (specifically SimCLR, MoCo, and BYOL), how they build off of eachother, and how these same concepts get reintroduced into more complex systems in the form of FlowCapsules.
SimCLR:
Standing for Simple Contrastive Learning of Visual Representations, SimCLR presents one of the most basic methods of this type of representation learning. The method trains an Encoder model based on the concept of positive samples and negative samples. Positive samples are data points that the model is trained to recognize as being the same as some piece of the dataset, and negative samples are the opposite, data points that the model is trained to separate from some piece of the dataset. The positive samples for models of this type are often generated by augmenting an image and the negative samples are the rest of the dataset.
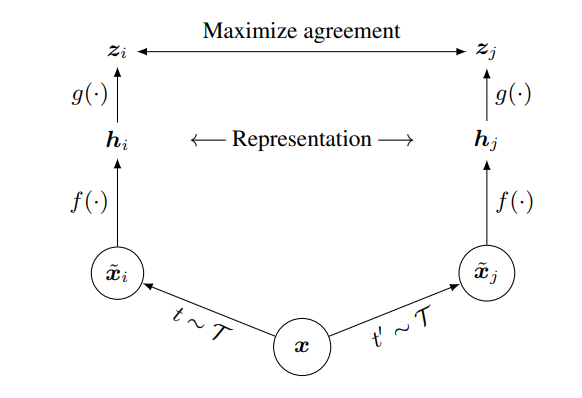
SimCLR uses a simple two stage network to achieve this training, with both an encoder (the piece of the model we are trying to train) and projection head . The input to the encoder is transformed with two augmentations and from the same family (rotations, translations, skews, etc.). This produces images and respectively from the chosen augmentations. These images are then passed to the encoder to generate the representations of each, with the specific model being chosen as ResNet in the original paper.
During training, the projection head is used to map these representations to a more comparable and lower dimensional space. The specific model is a simple one layer Multi-Layer Perceptron with ReLU activations.
The model is then trained on a form of contrastive loss between the two projection representations of the images. This is where the concept of positive samples and negative samples comes into place, and as mentioned before the positive sample is chosen as the other representation of the pair, and the negative samples are chosen as the representations from the rest of the batch. The loss contrasts these two groups with the projected sample and maximizes the similarity with the positive sample, and minimizes the similarity with the negative sample.
This is repeated for every single projected representation within a batch and ensures that different classes within the dataset are pushed away from other classes. This is one of if not the most important step within the model, since it limits the model from generating a constant representation for each image class (a situation in which the representation derived is the same for every single image), which would still work for the contrastive loss if not for the addition of the negative samples.
MoCo:
MoCo, standing for Momentum Contrast, works to improve on the weaknesses inherent to SimCLR’s batch limitations. Since SimCLR’s negative samples are the other examples within the batch, smaller batches will result in a lack of negative samples. MoCo amends this by removing the batch size dependence and moving towards a memory bank structure. The model holds the previous samples within a Queue of a predetermined maximum size which are then used for that same contrastive loss.
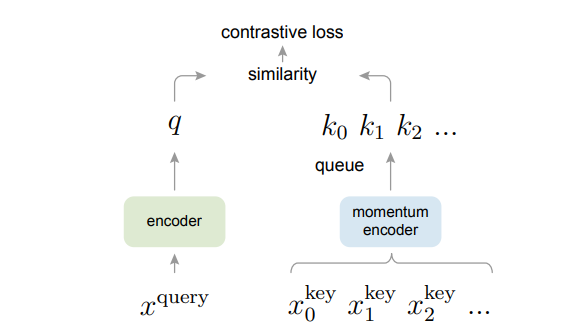
Due to the long-term use of each of these samples, the encoder structure also needs to be reformatted. The encoder is broken up into two encoders, a query encoder, generating current batch representations, and a key encoder, generating representations for each sample in memory. Given the same pair of augmented images, one is processed by the query encoder and one is processed by the key encoder and placed within the memory Queue (which if at maximum size simply removes the oldest sample). The momentum of the model takes action at training this key encoder, which is also called the momentum encoder. Rather than having its parameters trained directly, the key encoder trails behind the query encoder’s weights. This stops the model from generating and comparing representations that are too different due to a rapid change in parameter weights since the samples will be generated by different weights at each batch.
BYOL:
The issue with both of the above methods is inherent to negative samples in unsupervised tasks, which most often is found within false positives (samples that do share features that will be considered negative by default). These issues could theoretically be solved by removing the use of negative samples entirely, but then a new problem emerges. The point of the previous methods was not only to get an information-rich latent describing important features, but also to make sure that these latents are well separated to make their features noticeable. Without the use of negative samples, the models run into a problem of representation collapse, a scenario in which a model outputs identical embeddings for all inputs.
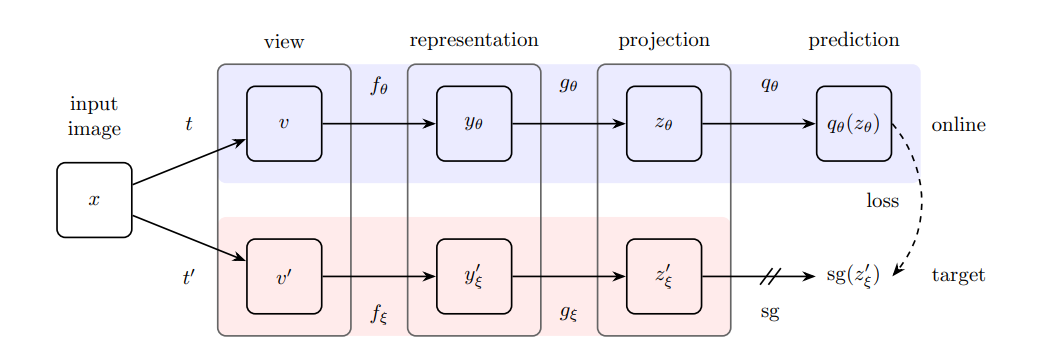
BYOL, standing for Bootstrap Your Own Latent, seeks to overcome this by making it incredibly hard for any form of constant embedding to form. This is done by introducing enough asymmetry and non-linearity and changing the goal from something discriminative to something predictive in nature. The model takes the branching nature of MoCo even further, with the method being split into an Online and Target Network, with weights and respectively.
Just like the previous two methods, two augmentations and are chosen from the same family of augmentations . These are each used to process an image and generated images and respectively. These are then passed through each model, each with a familiar system of an encoder and a projector .
The main change that the model provides then comes in how the output of the Online Network is handled. Instead of just comparing these two outputs, the model passes the output through a predictor and gets which acts as a prediction of . This provides enough asymmetry between both branches to avoid any sort of representation collapse even without using the negative samples.
The prediction and the Target output are then normalized before being compared in the loss.
The model uses a simple Mean Squared Error loss to define the difference between both branches. The total loss is calculated using the combined loss from comparing the pair in both possible orders.
BYOL also adopts the momentum learning from MoCo to help stabilize the training process and to further prevent the model from resorting to representation collapse. The momentum update allows the Online Network to have a stable yet still slow-moving target to train towards which is imperative due to the complexity of the branch.
FlowCapsules:
The main point of self-supervised image representation learning is finding a way to compress an image into a smaller latent space that only conveys its key features. If you have heard of them, this may lead to instant connections to Capsule Networks, an extension of Neural Networks with vector-based neurons that I have covered before. The foundation of these networks is built off of this concept of having neurons that represent features rather than basic local information so one should automatically come to the conclusion that these models could provide a lot of bonuses if used in conjunction with these representation learning methods. The main problem with this use case is one that is common in almost every AI model and the one that capsule networks are trying to fix, these representations aren’t interpretable. Using these representations instead of the basic CNN layer that Capsule Networks usually use would not provide as many improvements as one might think, since the information is still contained within the output in an unknown way. This limitation is where FlowCapsules come into play. FlowCapsules presents a method to generate the first layer of Capsules (vectors that represent key parts of the object within an image) in a geometrically grounded way, whereas other models simply use the output of the CNN. Although being limited to only videos as well as only single object datasets, these limitations help ground the representations learned in something that can be interpreted both by the computer, other models, and even us.
The model uses a system that is somewhere in between both the negative sample and predictor based methodologies that have been explored before. The model uses a single Encoder-Decoder line, broken up into an Image Encoder and a Mask Decoder, with the Image Encoder being used after training to generate the Primary Capsules. To avoid representation collapse, the model takes the prediction idea from BYOL even further and has the current frame’s information predict the movement that leads to the second frame.
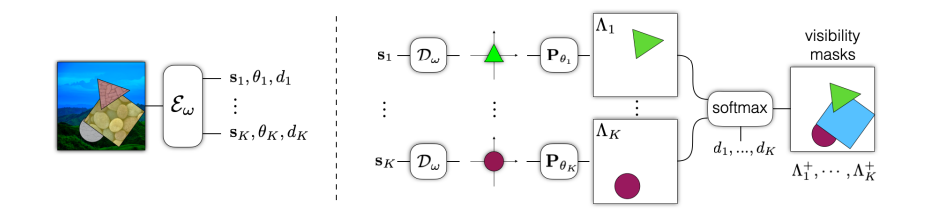
Image Encoder:
The Image Encoder is given an image and is tasked with outputting a collection of primary capsules. Each capsule is comprised of three parts, a vector which encodes the shape of the part, a pose vector which specifies the part-centric to image coordinate conversion, and a depth scalar which specifies inverse depth (larger for foreground objects).
The pose vector helps to define a transformation that can take the information from object-based coordinates to those of the image. The pose vector can be broken down into the translation , the rotation , and the scale change . This can then be used to generate a map which moves between image coordinates and part-centric coordinates .
Mask Decoder:
The mask decoder takes these capsules and generates a mask in image coordinates. The coordinate frame is defined as and the decoder processes each capsule and produces a mask for the part as shown below. The model chosen by the original paper was a simple MLP.
An added post-processing step is added to also avoid any issues with the motion occluding objects, the depth scalars are used to order each part. The visible portion of the -th part is defined below.
Training:
Given a pair of adjacent video frames and , two sets of capsules and are generated. A flow field is created to model the movement of each part between the frames. This is also facilitated by a mapping between the coordinate frames of both objects (which transitions from one object to image coordinates, and then to the other object’s coordinates). As well denotes the 2D normalized image coordinates.
Given this estimated flow, the pixels of are warped according to and compared to to form the contrastive loss.
Along with this general loss two regularizers are added to the total loss to make training more efficient. The first regularizer acts as a smoothness term and enhances gradient propagation, with the second regularizer encouraging part shapes to be centered at the origin.
Conclusion:
FlowCapsules presents the idea that the predictive nature of BYOL and itself are the key aspects of why the use of negative samples are not necessary to avoid collapses during training. Although simplicity is often viewed as the golden standard within AI design, BYOL can be seen as evidence that adding some level of complexity to a model can help to overcome the shortcomings that are persistent within simpler ones, as long as there is some mechanism to prevent the complexity from overtaking training. This can also be seen in FlowCapsules whose encoder structure is inherently very complex, but whose complexity is counteracted by the visual grounding and the training regularizers within the model creating something that can provide better results than the simpler alternatives that were first proposed.